|
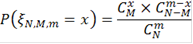
Таким образом, вероятность ошибиться при отвержении гипотезы 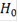 c помощью критерия c помощью критерия 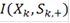 может быть вычислена по формуле: может быть вычислена по формуле:
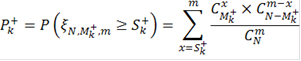
Таким образом, мы получили серию критериев с критическими статистиками 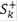 где k пробегает все значения, для которых где k пробегает все значения, для которых 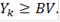 Логично из этих критериев выбрать критерий с наименьшей ошибкой первого рода: Логично из этих критериев выбрать критерий с наименьшей ошибкой первого рода:
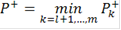
Аналогичным образом вводим альтернативную гипотезу 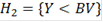 и обозначения: и обозначения:
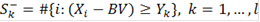 - набор критических статистик. - набор критических статистик.
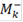 - количество значений в таблице меньше либо равных - количество значений в таблице меньше либо равных 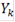 . .
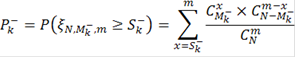
Это вероятности ошибиться, отвергнув нулевую гипотезу из-за слишком маленьких значений в выборке. Аналогично выбираем тот критерий, который имеет наименьшую вероятность ошибки первого рода.
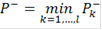
И, окончательно
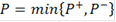
Причем, если 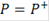 то, отвергнув нулевую гипотезу, целесообразно объявить исследуемый объект повысившим свою регуляцию. Если же то, отвергнув нулевую гипотезу, целесообразно объявить исследуемый объект повысившим свою регуляцию. Если же 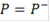 , то ген объявляется понизившим регуляцию. , то ген объявляется понизившим регуляцию.
Введем обозначения:
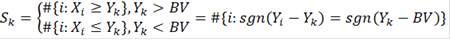
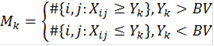
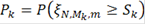
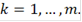
Тогда алгоритм можно описать следующим образом:
Упорядочиваем значения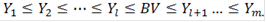
Идем по массиву значений и находим величины 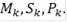
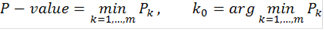
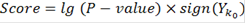
Итоговый ответ для каждого объекта - это скор, знак которого указывает на то, вероятность чего больше: того, что ген повысил или понизил экспрессию, а абсолютное значение, на то какова вероятность ошибиться при отвержении нулевой гипотезы. Скор близкий к нулю означает, что нулевая гипотеза, скорее всего, верна. Десятичный логарифм здесь взят для удобства. Т.е. например скор, равный 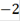 указывает нам, что если мы отвергнем гипотезу о том, что объект не изменил свою экспрессию и примем альтернативу указывает нам, что если мы отвергнем гипотезу о том, что объект не изменил свою экспрессию и примем альтернативу 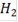 то мы ошибемся с вероятностью 0,01. Вероятность ошибки при принятии альтернативы то мы ошибемся с вероятностью 0,01. Вероятность ошибки при принятии альтернативы 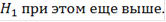
Перейти на страницу: 1 2 3 4
|
 На каком основании людей избирают лидерами, либо позволяют им становиться таковыми? Для объяснения этого явления был разработан ряд теорий, однако последние исследования сосредоточены на так называемых имплицитных теориях лидерства.
На каком основании людей избирают лидерами, либо позволяют им становиться таковыми? Для объяснения этого явления был разработан ряд теорий, однако последние исследования сосредоточены на так называемых имплицитных теориях лидерства. Для успешной работы фирмы на рынке необходимо не только определиться с целями, но и понять, как их можно достичь. Для этого надо очень хорошо изучить своего потребителя, а может, даже и создать новый тип потребителя.
Для успешной работы фирмы на рынке необходимо не только определиться с целями, но и понять, как их можно достичь. Для этого надо очень хорошо изучить своего потребителя, а может, даже и создать новый тип потребителя. Прежде всего менеджеру необходимо определить какой вид карьеры он предпочитает. Это и определит его стратегию. Если он менеджер знает, какое положение хочет занять через пять или даже десять лет, то можно определить направление действий и составить задачи, которых необходимо достичь.
Прежде всего менеджеру необходимо определить какой вид карьеры он предпочитает. Это и определит его стратегию. Если он менеджер знает, какое положение хочет занять через пять или даже десять лет, то можно определить направление действий и составить задачи, которых необходимо достичь.